
别被均值“欺骗”:描述统计方法论如何揭开客服数据背后的真相 | 数据炼金坊
本文共 3182 字
预计阅读时间 8 分钟

一家呼叫中心的周报上,AHT写着284秒,服务水平82%,满意度91分。运营主管把这张表发给总监,总监回复了两个字:还行。
没人知道这三个数字背后藏着什么,因为没人往里多看一眼。这张表每周都准时出现,每周都得到同样的回应,久而久之,看数据变成了一个确认仪式,而不是一个发现问题的过程。
这不是个别现象。绝大多数呼叫中心每天都在生产数据,但数据的加工方式停留在同一个动作:把原始数字变成均值,再把均值放进表格。这个动作做得越熟练,就越难察觉它正在掩盖什么。
更隐蔽的问题在于,均值会制造一种安全感。数字出来了,表格填满了,报告发出去了,一切看起来都在被监控、被管理——但实际上,真正关键的信息可能从来没有被读到过。
描述统计是干什么的?教科书会说,它是对数据集的基本特征进行汇总与描述的统计方法,包括集中趋势(均值、中位数、众数)、离散程度(标准差、方差、极差)和分布形态(偏度、峰度)。
这个定义没问题,但对呼叫中心管理者来说,更准确的说法是:描述统计是一套侦测“数字在撒谎”的工具。
当你只看均值,你看到的是所有人共同合谋出来的一个假象;当你同时看分布、看离散、看百分位,你才能看到真实发生了什么。
描述统计不是分析的终点,它是把数据从“摆设”变成“线索”的第一步转换。没有走完这一步,后续所有的决策讨论都在沙地上建房。
先从最常见的AHT说起。假设某团队月度AHT均值是300秒,主管觉得正常,因为上个月也是这个数。
但如果把这300秒背后的通话时长画成直方图,可能会出现一个双峰形态:大量通话集中在120秒左右,另一堆集中在580秒左右,均值300秒的那条线,正好落在两个峰之间的低谷。
换句话说,300秒这通电话在现实中几乎不存在,它只是两类完全不同通话的数学平均值。
短通话是什么?大概率是客户确认一个简单信息就挂断了。长通话是什么?可能是复杂投诉、情绪激动、反复核查。
这两类通话对座席的要求、对服务设计的启示、对排班资源的消耗,完全不在同一个维度。
把它们混在一起算均值,相当于把血压正常的人和血压极高的人平均一下,然后结论是“这群人血压还行”。
更实际的做法是先把通话按时长分段,看各段占比,再针对长尾通话单独分析原因——是某类业务天然耗时,是某些座席处理效率偏低,还是流程设计本身在制造冗余。
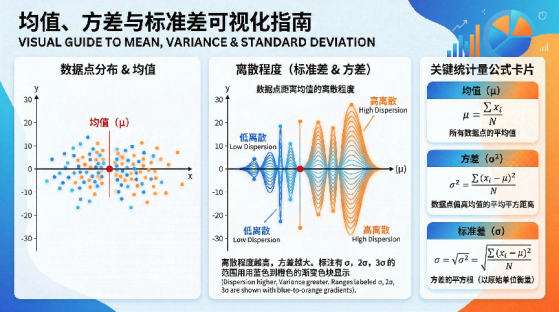

标准差在这里能做什么?它告诉你均值的可信程度。标准差小,均值有代表性;标准差大,均值就是个噪音。
一个团队AHT均值300秒,标准差180秒,这个均值基本没有参考价值,因为实际通话时长从60秒到660秒都有,说“平均300秒”等于什么都没说。
反过来,如果某座席AHT标准差极小,通话时长高度集中,这本身就值得注意——是处理流程被机械化固化了,还是这个座席在压缩服务时间?用标准差对比不同座席,还能快速识别出表现稳定和表现波动的人。
一个均值相近但标准差悬殊的对比,往往比单纯的均值排名更能说明谁在稳定出活、谁在靠运气拿到好数字。
标准差的另一个作用就是确定团队或小组的绩效离散程度。同样是月均AHT 300秒的两个班组,A组标准差40秒,B组标准差160秒,这两个数字放在绩效管理的语境里,意味着完全不同的管理任务。
A组的问题是整体水平能不能再提升,B组的问题是为什么同一个团队里会同时存在处理极快和处理极慢的坐席。
B组的均值和A组一样,但B组内部正在发生的事情要复杂得多——可能是新老座席混排导致经验断层,可能是某类高难度业务被不均匀地分配给了部分人,也可能是辅导资源没有集中在真正需要的人身上。
标准差大的团队,均值达标只是一个幻觉,它掩盖的是内部分化。把标准差纳入常规绩效报告,不是为了增加一列数字,而是为了让“团队表现正常”这个结论在说出口之前,先经过一次真实的检验。
中位数比均值更适合描述服务等待时长。等待时长的分布通常是右偏的:大多数客户等了十几秒就被接通了,但有一小批客户等了七八分钟。均值被这批长尾拉高,会高估大多数客户的实际体验。中位数不受离群值影响,更接近“典型客户等了多久”。
如果管理者只看均值等待时长,很可能得出“服务还好”的结论,但中位数和P90(第90百分位)放在一起看,才能发现有10%的客户正在经历一个完全不同版本的等待。
更进一步,可以追问这10%的客户在什么时段、打的是哪类业务,等待过长是因为人力不足、IVR路由设计问题还是某类话题集中爆发。
中位数给你定性结论,P90给你定位问题的边界,两个数字同时看才能得出可以行动的判断。
百分位数是客服场景里被严重低估的工具。行业里最通用的服务水平定义本质上就是百分位数:80%的电话在20秒内接通,说的是P80等待时长不超过 20秒。
但管理者很少把这个思维延伸出去。P90的通话时长、P95的等待时长、P99的问题解决时间——这些数字描述的是尾部体验,而客户投诉往往集中在尾部。
一家中心CSAT均值90分,听起来不错,但如果P10分位的满意度(即满意度最低的10%客户给出的分数)只有50分,这个群体的体验是一个独立的问题,均值把它压在了水面下。
百分位数分析还有一个容易被忽视的用途:用来设定合理的绩效目标区间。
把座席AHT的P25和P75定义为正常范围,落在P75以上的持续关注,落在P90以上的优先辅导,比拍一个全员统一的达标线要精准得多,也更符合团队内部真实的能力分布。
投诉数据是描述统计另一个容易出洞察的地方。投诉量的时间序列里通常藏着可识别的规律:哪些时段投诉率异常高,哪些业务类型的投诉在某个时间节点突然上升。
用月度均值看投诉,往往发现不了这些规律,因为峰值被稀释了。
把投诉量按周、按日画出来,趋势线和季节性波动就会浮现。比如每逢账单日前后投诉量集中爆发,这不是随机波动,是可以提前干预的规律。
更细一层,可以把投诉按问题类型分类后分别看各自的均值和标准差——有些类型的投诉量稳定,有些会在特定时段大幅波动。
稳定的问题说明流程有系统性缺陷,需要根因分析;波动的问题说明有触发条件,需要排查是产品变动、座席换班还是外部舆情带来的影响。
这两类问题的处理方式完全不同,但如果只看汇总投诉率,根本分不清楚自己面对的是哪种情况。
质检评分的分布形态值得单独说一下。一个团队的质检分通常呈现“左截断”的形态——分数很少低于70分,大量集中在85到95分之间,尾部很短。
这种分布不是因为座席表现真的集中在这个区间,而是因为质检员在评分时受到了某种无形的约束:打太低会引发申诉,打太高又说不过去,最终大家都默契地停在一个安全区。
如果真实服务质量的分布是这样,那说明质检系统测量的不是服务质量本身,而是评分员对分数的集体想象。
均值在这里不仅没用,它本身就是问题的一部分。识别这个问题的方法很直接:把质检分的频率分布图画出来,如果它不像一个自然的正态或轻度偏态分布,而是在某个分数段出现明显的人工堆积,这就是评分体系出了问题的信号,而不是座席表现的真实画像。
这时候需要重新校准质检标准,或者引入盲评机制打破评分员的心理预设。
所有这些分析,都不需要机器学习模型,不需要复杂的算法,只需要一个问题的习惯改变:在看到均值的时候,多追一句——这个均值背后的分布是什么形状?
这一句话问下去,直方图、箱线图、百分位数表格就都有了存在的理由。
工具不是门槛,Excel的数据分析工具包就能完成大部分计算,Python的几行代码可以把可视化做得更直观。
真正的门槛是愿不愿意承认“我之前看到的可能只是数据的表面”。
一个每周花十分钟看分布图的主管,和一个每周只看汇总表的主管,他们手里拿的数据完全相同,但他们看到的客服中心,是两个不同的地方。
真正的问题从来不是数据不够,而是有多少人愿意在均值停住的地方,再往里走一步。
- 2023-09-09
- 2023-09-09
- 2023-09-09
- 2023-09-16
- 2023-09-16
- 2023-09-09
- 2023-09-09
- 2023-09-09
- 2023-09-09
- 2023-09-09






